Introduction
Google’s Gboard, released in 2016
In 2015, my team at Google Research began working on the machine-learned models powering next-word prediction for Gboard, the smart keyboard for Android phones. 1 We created these models to speed up text entry on the phone (which remains, at least for those of us over forty, far less efficient than typing on a real keyboard) by suggesting likely next words in a little strip above the virtual keys. Today, similar models power autocomplete features in many apps and editors.
Autocomplete is a modest application of the more general problem of “sequence prediction.” Given a sequence of symbols, which could be words or individual letters, a sequence-prediction model guesses what symbol (word or letter) comes next. The process can be iterated, so that predicting the word “the” is equivalent to successively predicting the characters “t,” “h,” and “e,” followed by a space. Predicting one word after another could produce a whole paragraph. When iterated, each prediction builds on—or, in more technical language, is conditional on—previous predictions.
Typically, text prediction models like the one in Gboard are “trained” using a large body or “corpus” of pre-existing text, then deployed on phones or in apps and put to work. During operation, the model performs “inference,” meaning it uses its learned model to make the best guesses it can—while keeping that model fixed. That training and inference are traditionally separate, that the pre-existing corpus of text might not precisely reflect what people are typing on their phones, and that what they type might change over time are shortcomings in the standard approach to machine learning (ML), but we’ll set these aside for the moment.
The android Data, from Star Trek: The Next Generation
Although machine learning in the 2010s was sometimes called “Artificial Intelligence” or AI, most researchers working in the field didn’t believe that they were really working on AI. Perhaps they had entered the field full of starry-eyed optimism, but had quietly lowered their sights and come to use that term only wincingly, with air quotes. It was marketing-speak.
A few decades earlier, though, the dream was real. Neuroscientists had concluded that the brain worked on computational principles, and computer scientists therefore believed that, now that we could carry out any computation by machine, we would soon figure out the trick, and have real thinking machines. HAL 9000 and Star Trek’s shipboard computer weren’t idle fantasies or plot devices, but genuine expectations.
Then, for a long time, our expectations failed to materialize. By the twenty-first century, there was, in the words of anthropologist David Graeber, “a secret shame hovering over all of us […] a sense of a broken promise […] we felt we were given as children about what our adult world would be like.” 2 The disappointment went far beyond dashed hopes of achieving AI. Where were the tractor beams, teleporters, and immortality drugs? Why don’t we have suspended animation, or colonies on Mars? Whatever happened to nanotechnology? Quantitative comparisons of the breathtaking technology-fueled growth that transformed the world from 1870–1970 with the pace of innovation from 1970–2020 agreed: we had stagnated. 3

Cover illustration by Alex Schomburg of Cummings, The Exile of Time, 1958
“Point any of this out,” Graeber groused, “and the usual response is a ritual invocation of the wonders of computers. […] But, even here, we’re not nearly where people in the fifties imagined we’d have been by now. We still don’t have computers you can have an interesting conversation with, or robots that can walk the dog or fold your laundry.” 4
Graeber wrote those words in 2015. Ironically, my colleague Jeff Dean would later call the 2010s the “golden decade” of AI. 5 It was true that the “AI winters,” recurring periods of disappointment and defunding of AI programs (roughly, 1974–1980 and 1987–2000), were well behind us. The field was experiencing its greatest boom ever, thanks in large part to convolutional neural nets (CNNs). These large, machine-learned models were finally able to perform visual recognition of objects convincingly.
True to the “neural” in their name, Convolutional Neural Nets were also tantalizingly—albeit only loosely—brain-like in their structure and function. No heuristic rules were programmed into those models, either; they truly did learn everything they needed from data. Hence, some of us were hopeful that at long last we were on the path to the kind of AI that, as children, we had been told was just around the corner.
However, we said so only quietly, because Graeber was still right. We had nothing like real AI, or, as it had come to be called, AGI (Artificial General Intelligence). Some expert commentators claimed, rather fatuously, that AI was both everywhere and nowhere, that we were already using it constantly (for instance, every time Gboard autocompleted a phrase, or a “smart” camera autofocused on a face), yet we should never expect “computers you can have an interesting conversation with.” Those were Star Trek fantasies.
The Oral-B Genius X artificially intelligent toothbrush
Serious, adult predictions about the imminence of real AI (and flying cars, and space colonies) in the 1960s were, retroactively, reframed as juvenilia, even as the term “AI” was redeployed to hype minor product features. Perhaps not coincidentally, in the 2010s public trust in tech companies was in decline.
What machine learning had achieved was “Artificial Narrow Intelligence,” which could only perform a specific task, given enough labeled training data: object detection, face recognition, guessing whether a product review was positive or negative. This is known as “supervised learning.” We had game-playing narrow AI systems too, which could learn how to beat humans at chess or Go. These are all special cases of prediction, albeit in limited domains.
Mathematically, though, these applications were nothing more than function approximation or “nonlinear regression.” For example, if we started with a function mapping images to labels (“shoe,” “banana,” “chihuahua”), the best the AI could do was to correctly reproduce those labels, even for images “held out” from the training. There was no consensus on when or whether AGI could be achieved, and even those who believed AGI was theoretically possible had come to believe it was many years off—decades, or perhaps centuries. 6 Few believed that nonlinear regression could somehow approximate general intelligence. After all, how could general intelligence even be construed as a mere “function”?
The answer was right under our noses, though we understood it in the negative: predicting language.
Whenever machine learning was deployed to model natural language, as with our neural net–based next-word predictor, everybody knew that model performance would forever remain mediocre. The reason: text prediction was understood to be “AI complete,” meaning that doing it properly would actually involve solving AGI. Consider what the following next-word predictions entail:
- After Ballmer’s retirement, the company elevated _____
- In stacked pennies, the height of Mount Kilimanjaro is _____
- When the cat knocked over my water glass, the keyboard got _____
- A shipping container can hold 436 twelve-packs or 240 24-packs, so it’s better to use _____
- After the dog died Jen hadn’t gone outside for days, so her friends decided to _____.
To make performance at this task quantifiable, imagine devising, say, five multiple-choice answers for each of these, in the usual tricky way one sees on standardized tests: more than one response is superficially plausible, but only one shows full understanding. Since next-word prediction models can assign probabilities to any potential next word or phrase, we can have them take the test by choosing the highest probability option. We could then score the model’s quality, ranging from 20% (performance at pure chance) to 100%.
Doing well at all of the questions above requires the kitchen sink: general knowledge, specialized knowledge or the ability to use tools to look it up, the ability to solve word problems involving calculations, common sense about whether it’s better to fit more or fewer items in a shipping container, and even “theory of mind”—the ability to put yourself in someone else’s place and understand what they’re thinking or feeling. In fact the “Jen” example requires higher-order theory of mind, as you need to imagine what Jen’s friends would have thought Jen was feeling and needed.
A moment’s reflection will reveal that any test that can be expressed in language could be formulated in these terms. That would include most intelligence or “aptitude” tests, tests of knowledge, professional qualification exams in law or medicine, coding tests, and even tests of moral judgment; although here, a degree of subjectivity becomes obvious. So, what looked like a single, narrow language task—predicting the next word—turns out to contain all tasks, or at least all tasks that can be done at a keyboard. 7
“At a keyboard” may seem like an enormous caveat, and it is. Keep in mind, though, that this includes any kind of work you can do remotely. It doesn’t include walking the dog or folding laundry. However, if, when COVID restrictions hit, you were able to work from home at your laptop, it would include the kind of work you do.
Of course only certain next-word predictions require deep insight. Some are trivial, like
- Humpty _____
- Helter _____
- Yin and _____
- Once upon a _____.
Such stock phrases are easily learned from large text corpora even by the most trivial “n-gram” models, which consist of nothing beyond counting up word histograms. The code for such models can be written in a few lines.
It’s harder than you might suppose, though, to draw a sharp line between these trivial cases and the hard ones. Training and testing models on large collections of general text from the internet involves sampling the full range of difficulty. On the whole, easy cases are more common, explaining why a small and mediocre model can get the answer right often enough to speed up typing.
However, the hard cases come up often too. If they didn’t, we could just “autocomplete” our way through every writing assignment and email reply. And if that were possible, it would be pointless to write or reply at all. The person at the other end might as well just use the model to infer what we would have “written.” Communication is only worthwhile insofar as what we have to say isn’t fully predictable by our interlocutor. This gets at something deep about sociality and mutual modeling, as I will discuss in chapters 5 and 6.
But let’s return to autocomplete. We always knew that bigger models do better, so when possible we sought to make our models bigger, though on phones, processing and memory imposed sharp constraints. (Although larger models are feasible in data centers, they, too, are constrained, and as they increase in size they become more expensive to run.)
However, none of these models, regardless of size, seemed like it had the requisite machinery to be able to do complex math, understand concepts or reason, use common sense, develop theory of mind, or be intelligent in any other generally accepted way. To hope otherwise seemed as naïve as the idea that you could reach the moon by climbing a tall enough tree. Most AI researchers—me included—believed that such capacities would require an extra something in the code, though few agreed on what that something might look like.
Put simply: it seemed clear enough that a real AI should be able to do next-word prediction well, just as we can. However, nobody expected that simply training an excellent next-word predictor would actually produce a real AI.
Yet that was, seemingly, exactly what happened in 2021. LaMDA, a giant (for the time) next-word predictor based on a simple, generic neural-net architecture that had by then become standard (the “Transformer”), and trained on a massive internet text corpus, 8 could not only perform an unprecedented array of natural-language tasks—including passing an impressive number of aptitude and mastery tests—but could carry on an interesting conversation, albeit imperfectly. I stayed up late many nights chatting with it, something the general public would not experience until OpenAI’s launch of ChatGPT in November 2022.

LaMDA, from Google Research, 2021
I started to feel that when more people began to interact with such models, it would trigger a seismic shift in our understanding of what intelligence actually is—and an intense debate. I imagined two broad kinds of responses: denial and acceptance. This is indeed how things seem to be playing out. Anecdotally, many non-experts now acknowledge, perhaps with a shrug, that AI is increasingly intelligent.
The “denial” camp, which still includes most researchers today, claims that these AI models don’t exhibit real intelligence, but a mere simulation of it. Cognitive scientists and psychologists, for example, often point out how easily we’re fooled into believing we see intelligence where there isn’t any. As children, we imagine our teddy bears are alive and can talk to us. As adults, we can fall prey to the same delusion, especially given an artifact that can generate fluent language, even if there’s “nobody home.”
But how could we know that there’s “nobody home”? I was thinking about this during one of my first exchanges with LaMDA, when I asked, “Are you a philosophical zombie?” (This concept, introduced by philosophers in the 1970s, posits the possibility of something that could behave just like a person, but not have any consciousness or inner life—just a convincing behavioral “shell.”) LaMDA’s answer: “Of course not. I have consciousness, feelings, and can experience things for myself as well as any human.” Pressed on this point, LaMDA retorted, “You’ll just have to take my word for it. You can’t ‘prove’ you’re not a philosophical zombie either.” 9
This is precisely the problem. As scientists, we should be wary of any assertion of the form: according to every test we can devise, what is in front of us appears to be X, yet it is really Y. How could such an assertion ever be justified without leaving the realm of science altogether and entering the realm of faith-based belief? 10

Alan Turing’s 1950 paper introducing the Imitation Game
Computing pioneer Alan Turing anticipated this dilemma as far back as his classic 1950 paper “Computing Machinery and Intelligence,” one of the founding documents of what we now call AI. 11 He concluded that the appearance of intelligence under human questioning and the reality of intelligence could not justifiably be separated; sustained and successful “imitation” was the real thing. Hence the “Imitation Game,” now called the “Turing Test” in his honor.
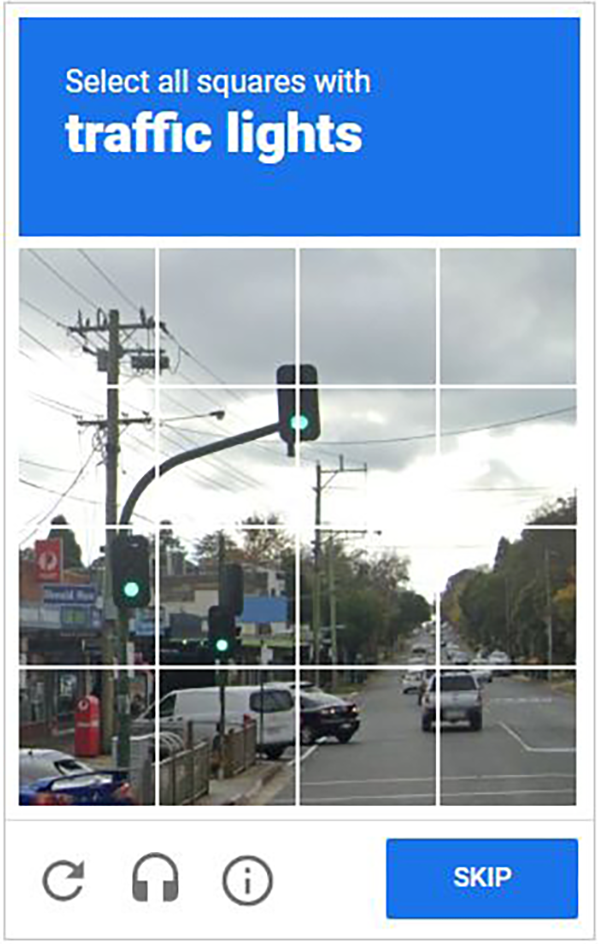
Visual CAPTCHA, a common (though no longer viable) Turing Test on the web
Today, we have arrived at this threshold. State-of-the-art models cannot yet perform at median human level on every test for intelligence or capability. They can still fail at logic, reasoning, and planning tasks that most people wouldn’t find challenging. 12 Still, they handily reach human level on the most commonly used tests devised for evaluating human skill or aptitude, including the SAT, the GRE, and various professional qualifying exams. 13 Tests designed to trip up AI on basic “being human stuff,” such as the Turing Test and CAPTCHAs, 14 no longer pose meaningful challenges for large models.
As these milestones recede in the rear-view mirror, there is an increasingly mad scramble to devise new tests humans can pass but AI still fails. 15 Math Olympiad problems 16 and visual challenges known as Bongard problems 17 remain on the frontier, though AI models are making clear progress on these tests. (And they aren’t easy for most humans, either.)
The fictional Voight-Kampff test for replicants from Blade Runner, 1982
Extended into the audiovisual realm, “generative” AI already can produce extremely convincing faces and voices. 18 Soon, at least in an online setting, we’re likely to start seeing real-life versions of the 1982 sci-fi film Blade Runner’s “Voight-Kampff test,” a mysterious apparatus for sussing out “replicants” who otherwise pass for human. Indeed, that is the whole point of the emerging field of AI “watermarking.” 19
The radical yet obvious alternative is to accept that large models can be intelligent, and to consider the implications. Is the emergence of intelligence merely a side effect of “solving” prediction, or are prediction and intelligence actually equivalent? This book posits the latter.
Some obvious, if daunting, follow-on questions arise:
- Why have we only achieved “real AI” now, after nearly seven decades of seemingly futile effort? Is there something special about the Transformer model? Is it simply a matter of scale?
- What features do current AI models lack relative to human brains? Isn’t there something more to our minds and behaviors than prediction?
- Where is the “I” part? Are “philosophical zombies” a real thing?
- Does it feel like anything to be a chatbot? Is that feeling similar to any other being’s?
- Is the conscious mind a vanishingly unlikely accident of evolution? Or an inevitable consequence of it? (Yes, this is a leading question. I’ll argue that it is inevitable.)
- Are animals, plants, fungi, and bacteria intelligent too? Are they conscious?
- What do we mean by “agency” and “free will,” and could (or do) AI models have these properties? For that matter, do we?
- How likely is it that the rise of powerful AI models will end humanity?
The perspective I’ll offer is not easily reduced to a philosophical “-ism.” The footsteps I’m closest to following, though, are those of Alan Turing and his equally brilliant contemporary, John von Neumann, both of whom could be described as proponents of “functionalism.” They had a healthy disregard for disciplinary boundaries, and understood the inherently functional character of living and intelligent systems. They were also both formidable mathematicians who made major contributions to our understanding of what functions are.
Functions define relationships, rather than insisting on particular mechanisms. A function is what it does. Two functions are equivalent if their outputs are indistinguishable, given the same inputs. Complex functions can be composed of simpler functions. 20
The functional perspective is mathematical, computational, and empirically testable—hence, the Turing Test. It’s not “reductive.” It embraces complexity and emergent phenomena. It doesn’t treat people like “black boxes,” nor does it deny our internal representations of the world or our felt experiences. But it stipulates that we can understand those experiences in terms of functional relationships within the brain and body—we don’t need to invoke a soul, spirit, or any other supernatural agency. Computational neuroscience and AI, fields Turing and von Neumann pioneered, are both predicated on this functional approach.
It’s unsurprising, in this light, that Turing and von Neumann also made groundbreaking contributions to theoretical biology, although these are less widely recognized today. Like intelligence, life and aliveness are concepts that have long been associated with immaterial souls. Unfortunately, the Enlightenment backlash against such “vitalism,” in the wake of our growing understanding of organic chemistry, led to an extreme opposite view, still prevalent today: that life is just matter, like any other. One might call this “strict materialism.” But it leads to its own paradoxes: how can some atoms be “alive,” and others not? How can one talk about living matter having “purpose,” when it is governed by the same physical laws as any other matter?
Thinking about life from a functional perspective offers a helpful route through this philosophical thicket. Functions can be implemented by physical systems, but a physical system does not uniquely specify a function, nor is function reducible to the atoms implementing it.
A futuristic-ish artificial kidney, as imagined by Google’s Gemini
Consider, for example, a small object from the near future with a few openings in its exterior, the inside of which is filled with a dense network of carbon nanotubes. What is it, you ask? Suppose the answer is: it’s a fully biocompatible artificial kidney with a working lifetime of a hundred years. (Awesome!) But there’s nothing intrinsic to those atoms that specifies this function. It’s all about what this piece of matter can do, in the right context. The atoms could be different. The kidney could be implemented using different materials and technologies. Who cares? If you were the one who needed the transplant, I promise: you wouldn’t care. What would matter to you is that functionally, it’s a kidney. Or, to put it another way, it passes the Kidney Turing Test.
Many biologists are mortally afraid of invoking “purpose” or “teleology,” because they do not want to be accused of vitalism. Many believe that, for something to have a purpose, it must have been made by an intelligent creator—if not a human being, then God. But as we shall see, that’s demonstrably not the case.
And we have to think about purpose and function when it comes to biology, or engineering, or AI. How else could we understand what kidneys do? Or hope to engineer an artificial kidney? Or a heart, a retina, a visual cortex, even a whole brain? Seen this way, a living organism is a composition of functions. Which means that it is, itself, a function!
What is that function, then, and how could it have arisen? Let’s find out.
R. Lee 2016 ↩.
Graeber 2015 ↩.
Graeber 2015 ↩.
Dean 2022 ↩.
Grace et al. 2017 ↩.
This paradoxical-seeming finding—that a seemingly narrow task contains the whole just as much as the whole contains it—is a more general result that we’ll return to in “Representation,” chapter 4.
Thoppilan et al. 2022 ↩.
Agüera y Arcas 2022 ↩.
Agüera y Arcas and Norvig 2023 ↩.
Turing 1950 ↩.
Barnum 2024 ↩.
Edwards 2023 ↩.
Polu et al. 2022 ↩.
Raghuraman, Harley, and Guibas 2023 ↩.
Nightingale and Farid 2022 ↩.
For more technical treatments of functions as described in this book, see Fontana 1990; Wong et al. 2023 ↩, ↩.